Наступает эпоха централизованных оперативных систем,
в которых вся совокупность данных
доступна немедленно всем потребителям.
Преимущества иерархических баз данных (ИБД) проявляются в относительно простых задачах хранения и обработки малосвязанной информации, например, обычно применяется для сбора анализа информации, поступающих от АСУ ТП, лабораторий и других точечных источников данных.
Для такой информации характерна независимость источника данных и большой объем данных во времени, например, временные ряды стоимости активов, акций, валют тоже неплохо структурируются и описываются ИБД.
За счет чего обычно достигается увеличение скорости и уменьшение объема хранения?
В реляционной базе данных подобная информация часто имеет одинаковую структуру — очень длинные таблицы (миллионы и более записей) с большим числом полей, имеющих относительные небольшие справочники. Например таблицу такого вида
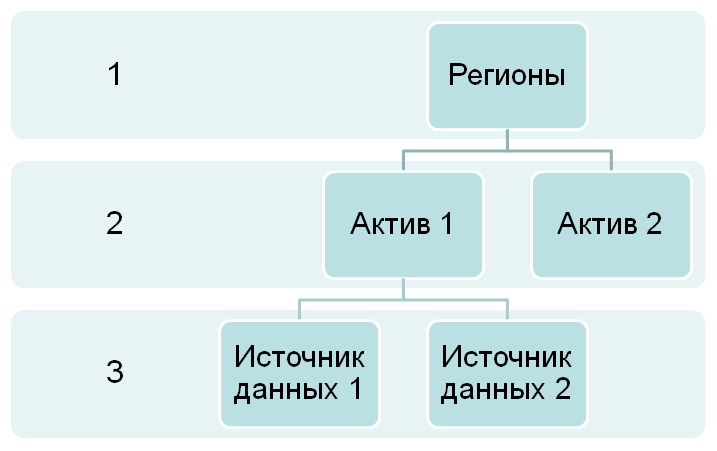
1. регион
2. актив (завод, предприятие, офис)
3. иерархия объектов управления актива (установки, здания, оборудование, виды бизнеса)
4. датчики или ручные системы сбора данных временных рядов
В результате создается таблица с большим числом полей, которые имеют мало вариантов (обычно из справочников). Это создает следующие трудности для реляционных БД
— неоправданно большой объем таблицы и индексов
— снижение скорости чтения больших объемов информации
— большие потери времени и ресурсов на безопасность хранения данных
В то же время ИБД делают по сути один индекс — иерархию структуры динамических данных, в итоге и поиск, и чтение больших объемов информации происходит оптимальным образом.
О недостатках ИБД можно прочесть здесь.
Иерархическая база данных — типичная модель