
Несправедливость перенести сравнительно легко;
что нас ранит по-настоящему — это справедливость.
Генри Луис Менкен
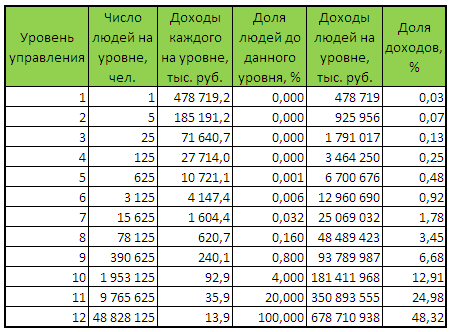
Ранее я дал методику расчета неравенства с помощью коэффициента Джини и кривой Лоренца. Добавив среднюю зарплату по России, да и по любой другой стране, можно оценить распределение текущих доходов между гражданами России. Ниже дана таблица такого расчета, которая соответствует
— коэффициенту Джини (0,42) для России
— средней зарплате за 2011 год в России (23 тыс. рублей)
— предположению (непринципиальному), что каждый следующий уровень управления руководит 5 специалистами
— доходы каждого следующего уровня управления растут в геометрической прогрессии, вычисляемой из коэффициента Джини
Общее число работающих в таблице около 60 млн., что примерно соответствует ситуации в России (у нас где-то 40 млн. пенсионеров и порядка 30 млн. детей и студентов). Понятно, что эти суммы тоже как-то распределены по своему уровню, но в целом уже отражают уровень доходов больших групп. Легко заметить, что доходы от 90 тыс. рублей ($3000), которые можно сравнивать со среднеевропейскими имеют 4% работающих граждан России, то есть порядка 2,4 млн. человек.
Таблица распределения месячных доходов населения по уровням управления в России

Зарплаты в России: http://luckyea.ucoz.ru/forum/17-294-1
90 тыс. рублей ($3000), которые можно сравнивать со среднеевропейскими имеют 4% полезная информация, то есть порядка 2,4 млн. человек.. Какая погрешность метода?
интегрально все должно сходиться, при больших доходах — небольшие изменения численности обеспеченных людей, думаю, что вряд ли больше 10-20% ошибка
Откуда взята статистика приведённых цифр (численность, доходы)?
Из фактических данных используются примерная численность работающих, средняя их зарплата, а распределение их по доходам рассчитано по текущему коэффициенту Джини
Буду признателен за методологию сбора данных, на правах падавана, обновленной статистки 13-14 годов. Как предложение?
Я брал обычные данные, но потом по ним считал коэффициенты аналитической кривой Лоренца, а уж из нее делал эту таблицу, в основном она более понятно дает данные по населению с большими доходами
Это именно то, что я сейчас пытаюсь как-то отрисовать: «распределение доходов жителей МО в верхней 20-и % группе с доходом свыше Х руб.»
https://docs.google.com/spreadsheets/d/1Qh1NIRWWHSCI6HvVc6k92RdNUjhnybEH4i5EUnTS41Y/pubhtml
Я правильно понимаю, что под «коэф.аналит.кривой» можно подразумевать 20-и % группы?
Что далее? Строить линию тренды, что бы получить уравнение кривой и брать интегралы по участкам? (Простите за мой excel)
Но как решается вопрос неявного распределения и вклада, допустим, внутри 20-и % группы? Там ведь может быть вообще что угодно?
в ссылке в этой статье — есть методика, я беру аналитическую кривую (однопараметрическую) для кривой Лоренца, решаю обратную задачу для этого параметра по текущим данным и далее можно просто считать по этой аналитической кривой все более мелкие участки
Мне кажется, если бы вы поделились таблицей ваших расчетов, можно было бы порадоваться и задать более уместные вопросы. Как вам предложение?
пришлите email, я вам файл Excel вышлю
bove.mayse@gmail.com
Я отправил вам письмо с файлом
Громадное спасибо. Очень хочу продолжить дискуссию, в приложении таких данных:
http://www.gks.ru/free_doc/new_site/population/trud/obsled/trud2013.htm
Есть в вашем распределении какая-то идеалистичность и красивые ряды-ёлочки, но вопрос о том, считать ли полученную «модель в лоб» достоверной в тех 20-30%, о которых было сказано, мне не удается. Т.е. с тем же ГКС в ссылке выше есть пересечения, но сам характер кривой не столь идеальный. И мне это, внутренне, понятно. Все же мы не муравьи.
Можем здесь, пошагово, разобрать ваше решение и приложить его к эмпирическим данным?
Сразу прошу учесть, что я не мат./эконом. отличник, со мной будет не легко, но смешно.
я сделал вам расчет по моей методике и выслал на почту, там можно подставлять разные значения, в том числе и первых 1,2 или %%, безусловно видна некоторая погрешность модели, но можно подобрать более сложную функцию, которая лучше опишет все точки и даст более точный прогноз
Честно говоря, я его не понял. Если удобнее это в почтовой переписке проговаривать — можно туда перейти. И так, что я вижу (по столбцам):
— Данные ГКС по среднему доходу 10-и % группы.
— кумулятивный средний доход децильной группы
— доля среднего дохода группы в %% от кумулятивного среднего дохода всех групп (? что имелось ввиду)
— доля среднего дохода в «распоряжении» следующих «более богатых» децильных групп от кумулятивного среднего дохода и поправочная/дополнительная сверх малая группа, просто для достроения кривой, неясно как вычисленная, но эта группа, как бы, 0.1% сверхбогатых получателей зарплаты (~ 30’000 человек), подчиняющихся распределению, заданному официальным Джини?
Как этот момент разобрать?
Далее, по последнему столбцу строится график, который я бы назвал… даже не знаю… «зависимость вклада группы в кумулятивный средний начисленный доход ранжированных по убыванию дохода граждан от среднего дохода децильной группы».
Далее, мы сводим полученную кривую в степенную функцию (1*x^y), где y = Джини, благодаря тому, что мы допускаем степенной характер ряда. В этом заключается модель?
По этому я предложил внести на этот график дополнительные данные — что говорит ГКС в таблице «Распределение численности работников по размерам начисленной заработной платыв экономике Российской Федерации за апрель 2013 г.»
http://www.gks.ru/free_doc/new_site/population/trud/obsled/trud2013.htm
И вот что у меня получается. И это кажется… Погрешностью?
В общем, что я делаю не так и почему — не понимаю. Фаил графика высылаю обратно.
кривая Лоренца строится так
по оси x — доля людей, причем самым малым значениям x соответствуют самые богатые, самым большим — самые бедные
по оси y — доля доходов этих людей, т.е. точки это просто доля их доходов от общего числа, например 20% людей (x) получает примерно 50% всех доходов (y)
кривая описывает эти точки функцией, зная функцию можно найти значения y при любых, даже малых, x, а не только по 10% интервалам
Вот кривые Лоренца построенные:
распред.1 — верхняя таблица ГКС из ссылки выше
распред.2 — нижняя таблица по 10%% группам
Ray — ваша модель несправедливого распределения
Сама логика вашей модели предлагает нам наличие дико богатого населения на верхушке пирамиды, но она неадекватна данным на промежутке 0…100 т.р.
я не понял ваши расчеты в Excel и на графиках, у меня 20% населения имеют 50% доходов, на вашем графике кривая Ray проходит мимо этой точки, то есть нарисована неверно
Обязательно перепроверю, действительно. Мне кажется, что зеленая линия — не кумулятивная. И сразу попробую сравнить с тем же BCG Global Wealth тра-ла-ла.
https://www.bcgperspectives.com/content/articles/financial_institutions_business_unit_strategy_global_wealth_2014_riding_wave_growth/?chapter=2#div_exhibit_4
не прикрепилось